
Web Scraping Deutsche Zeitungsartikel Frauenfussball
Vorhersage der zwei größten deutschen Tageszeitungen (BILD / Süddeutsche Zeitung) basierend auf der Wortwahl von Fußball-Artikeln
Frauenfußball, ein Thema, welches zunehmend relevanter wird und 2022 wieder in die Aufmerksamkeit von Medien rückte. Doch wie gehen unterschiedliche Tageszeitungen damit um?
Im folgenden versuchen wir, ein Modell zu trainieren, was auf den Wortschatz der größten zwei deutschen Tageszeitungen in Artikeln über Frauenfußball trainiert wurde. Wir werden anschließend versuchen, anhand von ausgewählten Wörtern zu ermitteln, in welcher Tageszeitung dieses Wort eher stand. Dies tun wir, indem wir Klassifikationsmodelle auf den Wortschatz trainieren. Im Zuge der Analyse werden wir auch einige explorative Analysen durchführen (Bigrams, Anzahl Artikel pro Tag etc.).
Zunächst importieren wir die nötigen Packages.
from bs4 import BeautifulSoup
import requests
import pandas as pd
import re
import matplotlib.pyplot as plt
import seaborn as sns
import nltk
from collections import Counter
import numpy as np
from datetime import date
Und erstellen unsere Funktionen fürs Scrapen:
def scrape_url(url, headers):
page = requests.get(url, headers=headers)
soup = BeautifulSoup(page.content, 'html.parser')
# print(soup)
return soup
def flatten(xss):
return [x for xs in xss for x in xs]
headers_fixed = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9,de;q=0.8,ru;q=0.7",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
Bild-Zeitung
soup = scrape_url('https://www.bild.de/suche.bild.html?type=article&query=Fu%C3%9Fball&resultsStart=10&resultsPerPage=1000', headers=headers_fixed)
Wenn wir im HTML code suchen, finden wir die class Elemente, die wir für die zu crawlenden Texte brauchen: Headlines (Überschriften), Kickers (so etwas wie Aufreißer / Über-Überschriften) und die “Entry contents”, also kurze Teaser für die Artikel.
headlines = soup.find_all(attrs={'class':'headline'})
kickers = soup.find_all(attrs={'class':'kicker'})
entry_content = soup.find_all(attrs={'class':'entry-content'})
headlines[1]
<span class="headline"><span>Schmid doppelt ausgebremst </span></span>
Um die Ergebnisse in ein dataframe-bereites Format zu bekommen, entfernen wir jeweils Leerzeichen rechts und links und bringen sie ins Listenformat.
headlines = [headlines[i].text.strip() for i in range(len(headlines))]
kickers = [kickers[i].text.strip() for i in range(len(kickers))]
entry_content = [entry_content[i].text.strip() for i in range(len(entry_content))]
headlines[1]
'Schmid doppelt ausgebremst'
Wir wollen auch das Datum des jeweiligen Nachrichtenposts abgreifen. das können wir mit soup.findAll, indem wir alle time tags finden und dann das datetime Attribut auslesen.
dates = [i["datetime"] for i in soup.findAll("time")]
dates[1:5]
['2022-08-09T14:21:36+02:00',
'2022-08-09T13:08:25+02:00',
'2022-08-09T12:32:05+02:00',
'2022-08-09T16:57:38+02:00']
Wir brauchen nur den ersten Teil vor dem “T”, da dort das Datum steht. Wir nehmen ihn uns also mit der .split Methode und konvertieren es zu einem datetime Format.
dates = [dates[i].split("T")[0] for i in range(len(dates))]
dates[1]
'2022-08-09'
dates = [pd.to_datetime(dates[i], format = '%Y-%m-%d') for i in range(len(dates))]
Jetzt können wir alles in einen pd.DataFrame zusammenfassen.
BILD_df = pd.DataFrame(list(zip(headlines, kickers, entry_content, dates)),
columns = ["headlines", "kickers", "entry_content", "date"])
print(len(BILD_df))
BILD_df.head()
983
| headlines | kickers | entry_content | date | |
|---|---|---|---|---|
| 0 | Uwe-Kumpel Bähre: „Das wird hochemotional“ | Trauerfeier für Seeler | Am Mittwoch werden im Volkspark viele Tränen ü... | 2022-08-09 |
| 1 | Schmid doppelt ausgebremst | Von Corona und Stage | Romano Schmid war einer der Gewinner der Vorb... | 2022-08-09 |
| 2 | Euro-Held Kostic verlässt Frankfurt | Der neue Klub, die Ablöse | Eintrachts Flügelstar Filip Kostic (29) steht ... | 2022-08-09 |
| 3 | Šeško unterschreibt in Leipzig bis 2028 | Wechsel offiziell | Was BILD berichtete ist jetzt fix: Benjamin Še... | 2022-08-09 |
| 4 | Schulz fehlt beim BVB-Training! | Nach Misshandlungs-Vorwürfen | Nach schweren Misshandlungs-Vorwürfen fehlt BV... | 2022-08-09 |
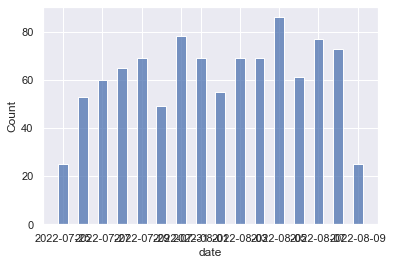
Wir können uns jetzt die Anzahl von Fußball-Nachrichten pro Tag anzeigen lassen.
# ## Data analysis
sns.set(rc={'figure.figsize':(11.7,8.27)})
sns.histplot(data=BILD_df, x="date", bins = len(set(BILD_df.date)), shrink=.5, discrete = True)
<AxesSubplot:xlabel='date', ylabel='Count'>
Wir werden jetzt Stoppwörter entfernen, um unserer Textanalyse durchzuführen:
from nltk.corpus import stopwords
stopwords=set(stopwords.words('german'))
def remove_stopwords(data):
output_array=[]
for sentence in data:
temp_list=[]
for word in str(sentence).split():
if word.lower() not in stopwords:
temp_list.append(word)
output_array.append(' '.join(temp_list))
return output_array
def clean_text(text):
text = text.replace('\\n','')
text = text.replace('\\','')
text = re.sub('(http:\/\/www\.|https:\/\/www\.|http:\/\/|https:\/\/)?[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,5}(:[0-9]{1,5})?(\/.*)?\s',
' __url__ ',text) #remove urls
text = re.sub('\W+',' ', text )
return text
headlines_clean = BILD_df.headlines.apply(clean_text)
headlines_clean = remove_stopwords(headlines_clean)
headlines_clean[0:3]
['Uwe Kumpel Bähre hochemotional',
'Schmid doppelt ausgebremst',
'Euro Held Kostic verlässt Frankfurt']
Wir können uns jetzt Bigrams basteln und die am meisten vorkommenden anzeigen lassen.
tokens = []
for headline in headlines_clean:
tokens.append(nltk.word_tokenize(headline))
#tokens
bigrams = []
for token in tokens:
bigrams += nltk.bigrams(token)
#bigrams
BILD_Bigrams = Counter(bigrams).most_common()[0:10]
BILD_Bigrams
[(('Live', 'Ticker'), 21),
(('St', 'Pauli'), 9),
(('live', 'TV'), 7),
(('Premier', 'League'), 6),
(('Champions', 'League'), 5),
(('Free', 'TV'), 4),
(('DFB', 'Mädels'), 4),
(('Gladbach', 'Star'), 3),
(('League', 'Quali'), 3),
(('Note', '2'), 3)]
Dies sind die am häufigsten in Paaren vorkommenden Worte. Vielleicht kann man hieraus schon erste Schlüsse ziehen, worüber die BILD gerne berichtet?
Nun für die zweitgrößte Deutsche Zeitung: Die Süddeutsche!
zunächst die html-Suppe, um headlines etc. herauszuziehen. Diesmal benutzen wir ein anderes Format, da wir mehrere Seiten durchscrapen müssen: Ein Loop für jede Seite der Suchergebnisse.
# explicit loop for debugging
# for i in range(1,11):
# print(i)
# print('https://www.sueddeutsche.de/news/page/'+str(i)+'?search=Fu%C3%9Fball&sort=date&all%5B%5D=dep&all%5B%5D=typ&all%5B%5D=sys&all%5B%5D=time')
soup = [scrape_url('https://www.sueddeutsche.de/news/page/'+str(i)+'?search=Fu%C3%9Fball&sort=date&all%5B%5D=dep&all%5B%5D=typ&all%5B%5D=sys&all%5B%5D=time', headers_fixed) for i in range(1, 21)]
Nun die Zeitangaben / Daten der News
dates_list = []
for sp in soup:
dates = [i.text.strip() for i in sp.find_all(attrs={'class':'entrylist__time'})]
dates = [dates[i].split("|")[0].strip() for i in range(len(dates))]
dates_list.append(dates)
# flatten list
dates = flatten(dates_list)
len(dates)
1000
Wir konvertieren es in pd.datetime Format
def make_date(d):
try:
return pd.to_datetime(d, format = '%d.%m.%Y').date()
except:
return pd.to_datetime("today").date()
dates = [make_date(dates[i]) for i in range(len(dates))]
dates = [pd.to_datetime(dates[i], format = '%Y-%m-%d') for i in range(len(dates))]
dates[0:5]
[Timestamp('2022-08-09 00:00:00'),
Timestamp('2022-08-09 00:00:00'),
Timestamp('2022-08-09 00:00:00'),
Timestamp('2022-08-09 00:00:00'),
Timestamp('2022-08-09 00:00:00')]
Jetzt holen wir uns noch die headlines und Teaser der Artikel und fassen es in einem DataFrame zusammen
headlines = flatten([i.find_all(attrs={'class':'entrylist__title'}) for i in soup])
headlines =[headlines[i].text.strip() for i in range(len(headlines))]
kickers = flatten([i.find_all(attrs={'class':'entrylist__overline'}) for i in soup])
kickers = [kickers[i].text.strip() for i in range(len(kickers))]
entry_content =flatten([i.find_all(attrs={'class':'entrylist__detail'}) for i in soup])
entry_content = [entry_content[i].text.strip() for i in range(len(entry_content))]
#len(kickers)
sueddeutsche_df = pd.DataFrame(list(zip(headlines, kickers, entry_content, dates)),
columns = ["headlines", "kickers", "entry_content", "date"])
sueddeutsche_df.head()
# check ob sie etwa gleich lang sind
len(sueddeutsche_df)
len(BILD_df)
978
983
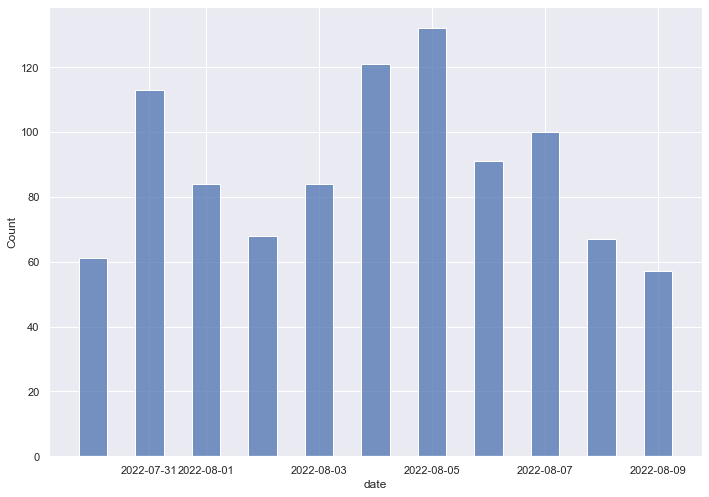
Jetzt können wir schon einmal die News pro Tag für diesen Suchbegriff für die Süddeutsche Zeitung anzeigen lassen
# ## Data analysis
sns.set(rc={'figure.figsize':(11.7,8.27)})
sns.histplot(data=sueddeutsche_df, x="date", bins = len(set(sueddeutsche_df.date)), shrink=.5, discrete = True)
<AxesSubplot:xlabel='date', ylabel='Count'>
Als nächstes bereinigen wir den Text um Stoppwörter…
headlines_clean = sueddeutsche_df.headlines.apply(clean_text)
headlines_clean = remove_stopwords(headlines_clean)
headlines_clean[0:10]
['Kanzler trifft paar wunde Punkte',
'FC Bayern verpflichtet Südkoreaner Lee fest',
'Dynamo Dresden erwartet Verl nächstes schweres Spiel',
'Ehrung Münchner EM Heldinnen Allianz Arena',
'Rauball kandidiert mehr BVB Präsidentenamt',
'Rauball kandidiert mehr BVB Präsidentenamt',
'Hodenkrebs OP Richter Hertha Training',
'Hodenkrebs OP Richter Mannschaftstraining',
'Kanzler macht DFB Druck Politisches',
'FC Bayern nimmt Vorbereitung Spiel Wolfsburg']
…und “tokenisieren”. Wir können uns wieder die häufigsten Bigrams anzeigen lassen
tokens = []
for headline in headlines_clean:
tokens.append(nltk.word_tokenize(headline))
# tokens
bigrams = []
for token in tokens:
bigrams += nltk.bigrams(token)
#bigrams
Sueddeutsche_Bigrams = Counter(bigrams).most_common()[0:10]
#Sueddeutsche_Bigrams
pd.DataFrame(list(zip(BILD_Bigrams, Sueddeutsche_Bigrams)),
columns = ["BILD", "Sueddeutsche"])
| BILD | Sueddeutsche | |
|---|---|---|
| 0 | ((Live, Ticker), 21) | ((FC, Bayern), 19) |
| 1 | ((St, Pauli), 9) | ((1, FC), 13) |
| 2 | ((live, TV), 7) | ((DFB, Frauen), 13) |
| 3 | ((Premier, League), 6) | ((RB, Leipzig), 10) |
| 4 | ((Champions, League), 5) | ((St, Pauli), 10) |
| 5 | ((Free, TV), 4) | ((VfB, Stuttgart), 10) |
| 6 | ((DFB, Mädels), 4) | ((Uwe, Seeler), 9) |
| 7 | ((Gladbach, Star), 3) | ((WM, Katar), 9) |
| 8 | ((League, Quali), 3) | ((Hertha, BSC), 8) |
| 9 | ((Note, 2), 3) | ((Voss, Tecklenburg), 7) |
Man erkennt ein gewisses Muster, über welche Vereine und Themen die beiden Zeitungen gerne berichten.
Als nächstes erstellen wir ein Prädiktives Modell. Vielleicht lässt sich ja anhand bestimmter Wörter vorhersagen, aus welcher Zeitung Überschriften stammen.
# create df and unite
BILD_df["source"] = "BILD"
sueddeutsche_df["source"] = "Sueddeutsche"
comb_df = pd.concat([BILD_df, sueddeutsche_df])
len(comb_df)
1961
Hierzu haben wir die Dataframes kombiniert, und eine ´source´ Spalte hinzugefügt, die wir nun versuchen werden “vorherzusagen”.
comb_df.head()
| headlines | kickers | entry_content | date | source | |
|---|---|---|---|---|---|
| 0 | Uwe-Kumpel Bähre: „Das wird hochemotional“ | Trauerfeier für Seeler | Am Mittwoch werden im Volkspark viele Tränen ü... | 2022-08-09 | BILD |
| 1 | Schmid doppelt ausgebremst | Von Corona und Stage | Romano Schmid war einer der Gewinner der Vorb... | 2022-08-09 | BILD |
| 2 | Euro-Held Kostic verlässt Frankfurt | Der neue Klub, die Ablöse | Eintrachts Flügelstar Filip Kostic (29) steht ... | 2022-08-09 | BILD |
| 3 | Šeško unterschreibt in Leipzig bis 2028 | Wechsel offiziell | Was BILD berichtete ist jetzt fix: Benjamin Še... | 2022-08-09 | BILD |
| 4 | Schulz fehlt beim BVB-Training! | Nach Misshandlungs-Vorwürfen | Nach schweren Misshandlungs-Vorwürfen fehlt BV... | 2022-08-09 | BILD |
Wir erstellen ein Test und ein Train Dataset, um das Modell zu trainieren. Y sind jeweils die “responses”, also BILD bzw. Sueddeutsche Zeitung.
#from sklearn import datasets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(comb_df["entry_content"], comb_df["source"], test_size=0.33, random_state=42)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
(1313,)
(648,)
(1313,)
(648,)
Nun können wir mit dem CountVectorizer eine Matrix mit Token Counts erstellen: Das ist quasi eine mathematische Darstellung der benutzten Wort-Tokens. Wie diese funktioniert ist hier auf Englisch gut erklärt: https://towardsdatascience.com/basics-of-countvectorizer-e26677900f9c
Danach nutzen wir den TF:IDF Transformer um eine TF-IDF zu erstellen:
- TF ist die relative Häufigkeit eines Tokens (Wortes) im Dokument: Wie viele Wörter des Dokumentes (der Überschrift) sind jeweils dieses bestimmte Token?
- IDF ist die inverse relative Frequenz, mit der ein Token (Wort) in all unseren Dokumenten vorkommt.
Die Logik dahinter ist also, dass wir die Gewichtung für häufig vorkommende Wörter durch das Multiplizieren des TF mit dem IDF reduzieren, sodass der TF-IDF-Score quasi eine Kennzahl der “Überraschung” für die Wörter angibt (besonders “markante” Wörter werden für das jeweilige Topic bzw. in unserem Fall für die jeweiligen Tageszeitungen hoch gewichtet).
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(X_train)
X_train_counts
<1313x4380 sparse matrix of type '<class 'numpy.int64'>'
with 18833 stored elements in Compressed Sparse Row format>
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
X_train_tfidf.shape
(1313, 4380)
Wir werden zunächst einen Multinomial Naive Bayes Classifier verwenden für die Klassifizierung
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB().fit(X_train_tfidf, y_train)
Wir benutzen jetzt zunächst Naive Bayes als Classifier. Wir können jetzt bereits anhand neuer “Dokumente” vorhersagen, welche Wörter in welcher Zeitung eher erscheinen würden. Wie bereits zu erwarten, sind Wörter wie “Schock” und “Skandal” prädiktiv für die BILD-Zeitung, die BILD redet lieber von “Mädels” und die Süddeutsche lieber von “Frauen”, und lustigerweise sind auch “Sex” und “seriös” recht passend zugeordnet :-)
docs_new = ['Bundesliga', 'Skandal', 'Schock', 'Niederlage', 'Bayern',
'Freiburg', "Mädels", "Frauen", "Sex", "seriös"]
X_new_counts = count_vect.transform(docs_new)
X_new_tfidf = tfidf_transformer.transform(X_new_counts)
predicted = clf.predict(X_new_tfidf)
pd.DataFrame(docs_new, predicted)
| 0 | |
|---|---|
| Sueddeutsche | Bundesliga |
| BILD | Skandal |
| BILD | Schock |
| Sueddeutsche | Niederlage |
| BILD | Bayern |
| Sueddeutsche | Freiburg |
| BILD | Mädels |
| Sueddeutsche | Frauen |
| BILD | Sex |
| Sueddeutsche | seriös |
Da dies in erster Linie ein Projekt war, um mir web scraping in Python beizubringen, hat die Analyse und das Modell keinen Anspruch auf Professionalität. Ich freue mich über konstruktive Kritik und hoffe, bald tiefer gehende Text-Mining-Projekte vorstellen zu können!